将HTML网页转换为PDF是好多人常见的一个需求,在浏览器上,我们可以通过浏览器的“打印”功能直接将网页复印输出为PDF。
而且倘若有多个网页就不好办了。
二补码软件
网路上存在好多将HTML转换为PDF的软件和工具。比较知名的有Carelib、wkhtmltopdf。
whtmltopdf
wkhtmltopdf真是一个优秀的HTML转换PDF工具。其利用Qt的WebKit渲染引擎,将HTML文档渲染导入为PDF文档或图象。
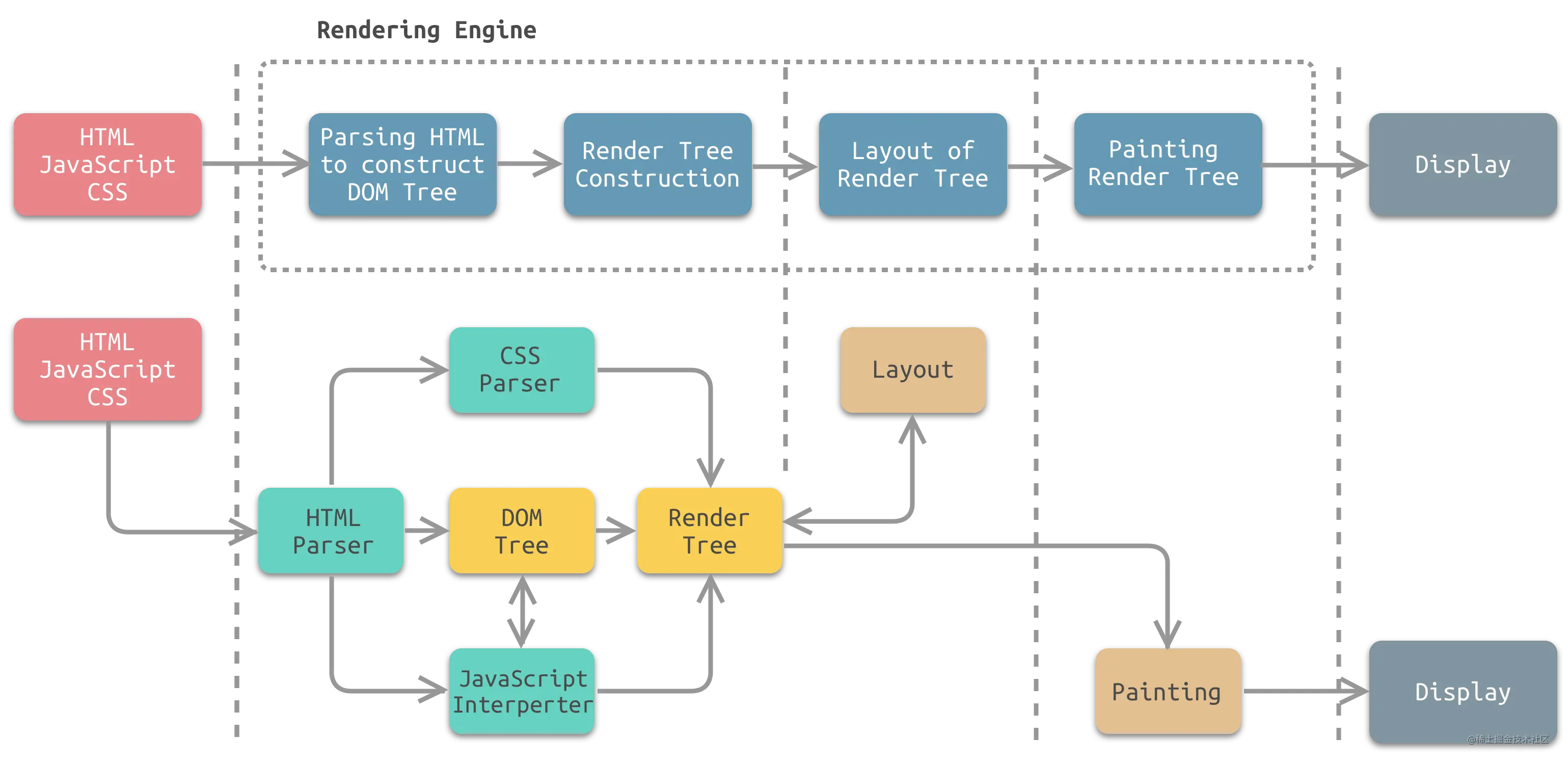
功能非常健全,而且因为使用的渲染引擎是Qt的WebKit,其无法对ES6的JavaScript代码提供支持,引起一些采用ES6编撰的HTML页面渲染不出实际的疗效来,致使州的先生最终舍弃了它。
Carelib
Carelib是一个电子书管理软件,其中提供了各种文档的转换工具linux内核网络栈源代码情景分析 pdf,所以可以利用其电子书转换工具来实现HTMl到PDF的转换。
这种都是用于桌面环境的二补码软件,假如要在Python中使用,要么使用Popen()方式调用那些二补码软件的命令,要么使用一些第三方的封装模块,例如:pdfkit、pypandoc等,这种第三方模块通过集成调用上述二补码软件ubuntu linux,封装了一些便捷Python调用的插口。
纯Python库实现
前面介绍的这些Python第三方模块其实可以挺好的进行HTML到PDF的转换工作,并且都须要额外在计算机上安装其他的二补码软件,好多男子伴并不喜欢这些调用方法。
不依赖于二补码软件的实现,有如下的方案:
xhtml2pdf
这是一个基于ReportLab、html5lib、PyPDF2等Python模块建立的HTML到PDF转换模块。才能挺好的支持HTML5、CSS2.1和部份CSS3句型。
由于是基于ReportLab模块进行的开发,其对英文的支持在个别环境下会有问题。并且因为开发人员的变更,模块的功能出现了一些断层。并且一直是一个极其棒的HTML转PDF模块。
weasyprint
这是一个用于HTML和CSS的可视化渲染引擎linux内核网络栈源代码情景分析 pdf,可以将HTML文档导入为复印标准的PDF文件。
xhtml2pdf模块也曾推荐使用这个模块来进行HTML转换PDF的工作。
这个模块功能很强悍、效果很出众,而且,模块的依赖项太多了:
州的先生至今没有在Windows笔记本上安装成功过!
浏览器方案
在上述两种方案中,二补码程序的可控制性稍有不足什么是linux,而纯Python实现的渲染解析则在功能上和依赖上不是有友好。
处理上述两种方案,我们能够采用第三种方法进行HTMl到PDF的转换。那就是利用Web手动化测试的浏览器内核和QtforPython的Web引擎来实现。
Web手动化的浏览器内核
使用Python的男子伴常常会使用Selenium、pyppeteer这两个Web手动化测试的模块来进行数据采集和Web手动化测试工作。
这两个模块都是拿来驱动一个真实的浏览器来进行网页的操作。正是基于此,我们可以调用浏览器中复印相关的API插口,来实现HTML转PDF的功能。
比如,在pyppeteer中可以根据下边示例的方法,打开一个HTML文档,之后将其转换为PDF文档:
Qt的Web引擎
在Qt5中,Qt使用新的Chromium内核取代了老旧的WebKit作为Web的渲染引擎。促使在Qt中进行可以现代化的浏览器开发。
利用于Qt的Python实现(PyQt5系列和PySide2系列),我们可以直接调用Qt中的Web引擎相关的插口。
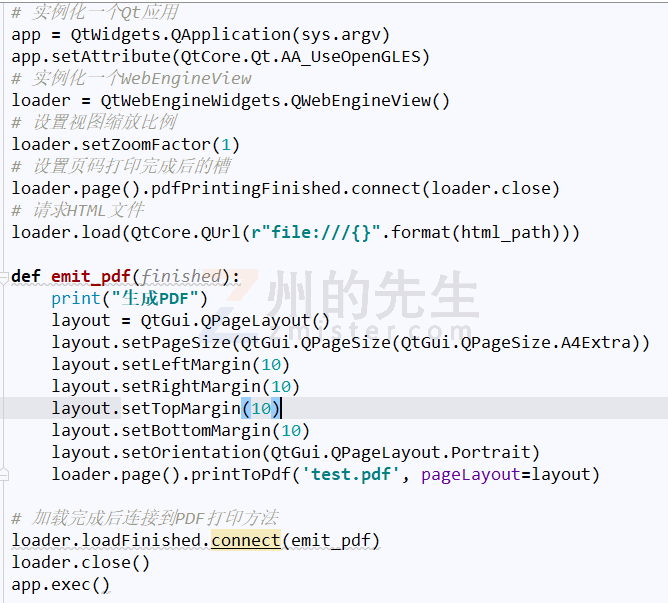
其中QtWebEngineWidgets子模块中的QWebEngineView()类提供了printToPdf方式供我们将网页复印为PDF文档,所以基于此,我们也可以使用PyQt5或PySide2进行HTML转换PDF,示例如下所示:
最后
在里面,州的先生介绍了3种在Python中转换HTML文档为PDF文档的方案,每种方案都有各自的优势和不足,正确地评估自己的需求之后选择合适的方案,也能填补其不足。
以上就是python将html转换为pdf的几种方式的详尽内容,更多关于python将html转换为pdf的资料请关注我们其它相关文章!





