在开始即将的讨论前,我先抛出几个问题:
假如你认为那些问题都很简单,都能很明晰的回答上来。这么很遗憾这篇文章不是为你打算的,你可以关闭网页去做其他更有意义的事情了。假如你感觉难以明晰的回答这种问题,这么就耐心地读完这篇文章,相信不会浪费你的时间。受限于个人时间和文章篇幅,部份议程假如我不能给出更好的解释或则已有专业和严谨的资料,就只会给出相关的参考文献的链接,请读者自行参阅。言归正传,我们的讨论从储存器的层次结构开始。
储存器的金字塔结构
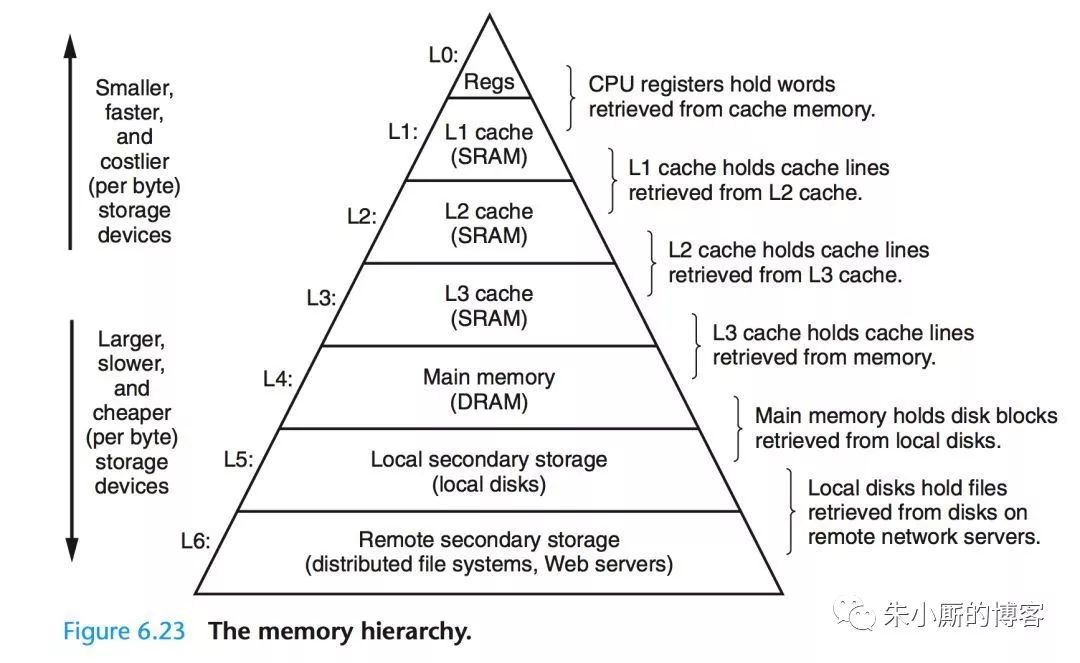
限于储存介质的存取速度和成本,现代计算机的储存结构呈现为金字塔型。越往塔顶,存取效率越高、但成本也越高,所以容量也就越小。得益于程序访问的局部性原理,这些节约成本的做法也能取得不俗的运行效率。从储存器的层次结构以及计算机对数据的处理方法来看,下层通常作为上层的Cache层来使用(广义上的Cache)。
诸如寄存器缓存CPUCache的数据,CPUCacheL1~L3层视具体实现彼此缓存或直接缓存显存的数据,而显存常常缓存来自本地c盘的数据。本文主要讨论c盘IO操作linux 文件锁,故只聚焦于LocalDisk的访问特点和其与DRAM之间的数据交互。
无处不在的缓存

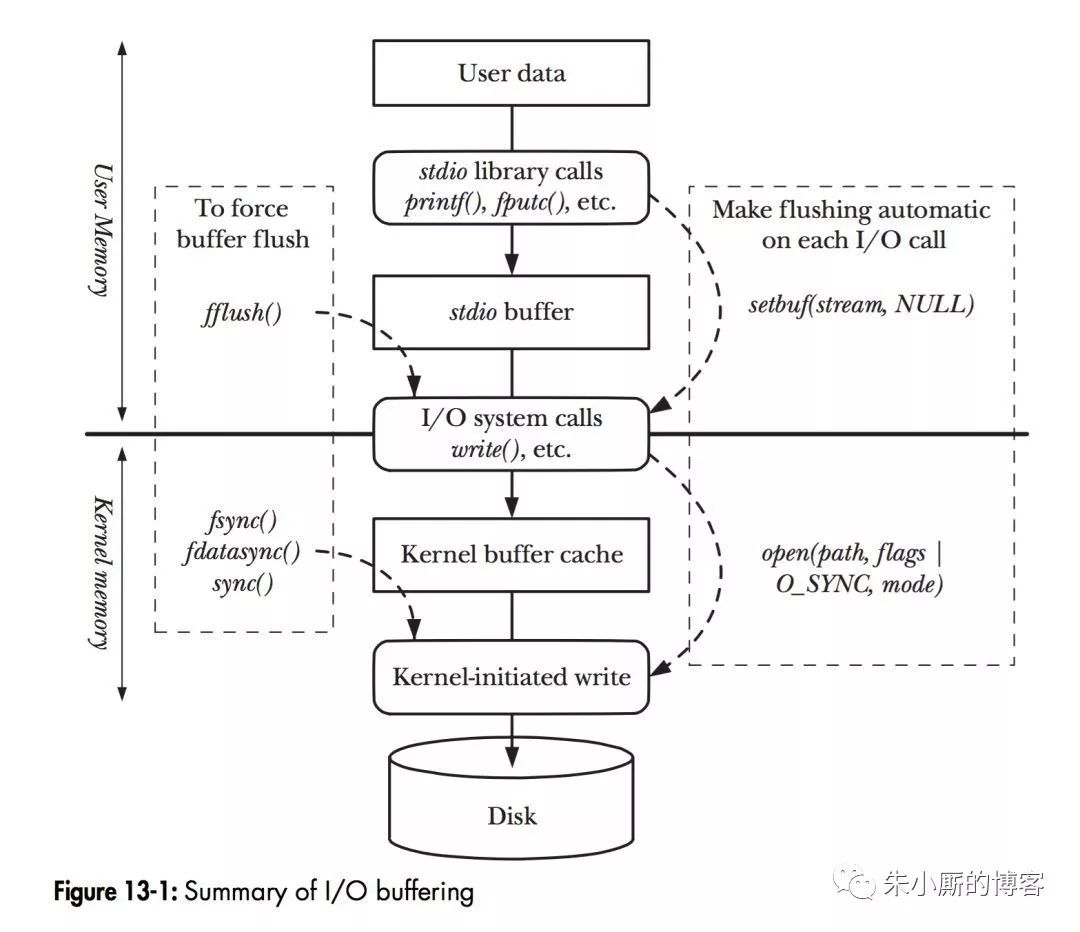
如图,当程序调用各种文件操作函数后,用户数据(UserData)抵达c盘(Disk)的流程如图所示。图中描述了Linux下文件操作函数的层级关系和显存缓存层的存在位置。中间的白色虚线是用户态和内核态的分界线。
从上往下剖析这张图,首先是C语言stdio库定义的相关文件操作函数,这种都是用户态实现的跨平台封装函数。stdio中实现的文件操作函数有自己的stdiobuffer,这是在用户态实现的缓存。此处使用缓存的缘由很简单——系统调用总是高昂的。假如用户代码以较小的size不断的读或写文件的话,stdio库将多次的读或则写操作通过buffer进行聚合是可以提升程序运行效率的。stdio库同时也支持fflush函数来主动的刷新buffer,主动的调用底层的系统调用立刻更新buffer里的数据。非常地,setbuf函数可以对stdio库的用户态buffer进行设置,甚至取消buffer的使用。
系统调用的read/write和真实的c盘读写之间也存在一层buffer,这儿用术语Kernelbuffercache来指代这一层缓存。在Linux下,文件的缓存习惯性的称之为PageCache,而更低一级的设备的缓存称之为BufferCache.这两个概念很容易混淆,这儿简单的介绍下概念上的区别:PageCache用于缓存文件的内容,和文件系统比较相关。文件的内容须要映射到实际的化学c盘,这些映射关系由文件系统来完成;BufferCache用于缓存储存设备块(例如c盘磁道)的数据,而不关心是否有文件系统的存在(文件系统的元数据缓存在BufferCache中)。
综上,既然讨论Linux下的IO操作,自然是跳过stdio库的用户态这一堆东西,直接讨论系统调用层面的概念了。对stdio库的IO层有兴趣的朋友可以自行去了解。从上文的描述中也介绍了文件的内核级缓存是保存在文件系统的PageCache中的。所以前面的讨论基本上是讨论IO相关的系统调用和文件系统PageCache的一些机制。
Linux内核中的IO栈
这一小节来看Linux内核的IO栈的结构。先上一张概貌图:
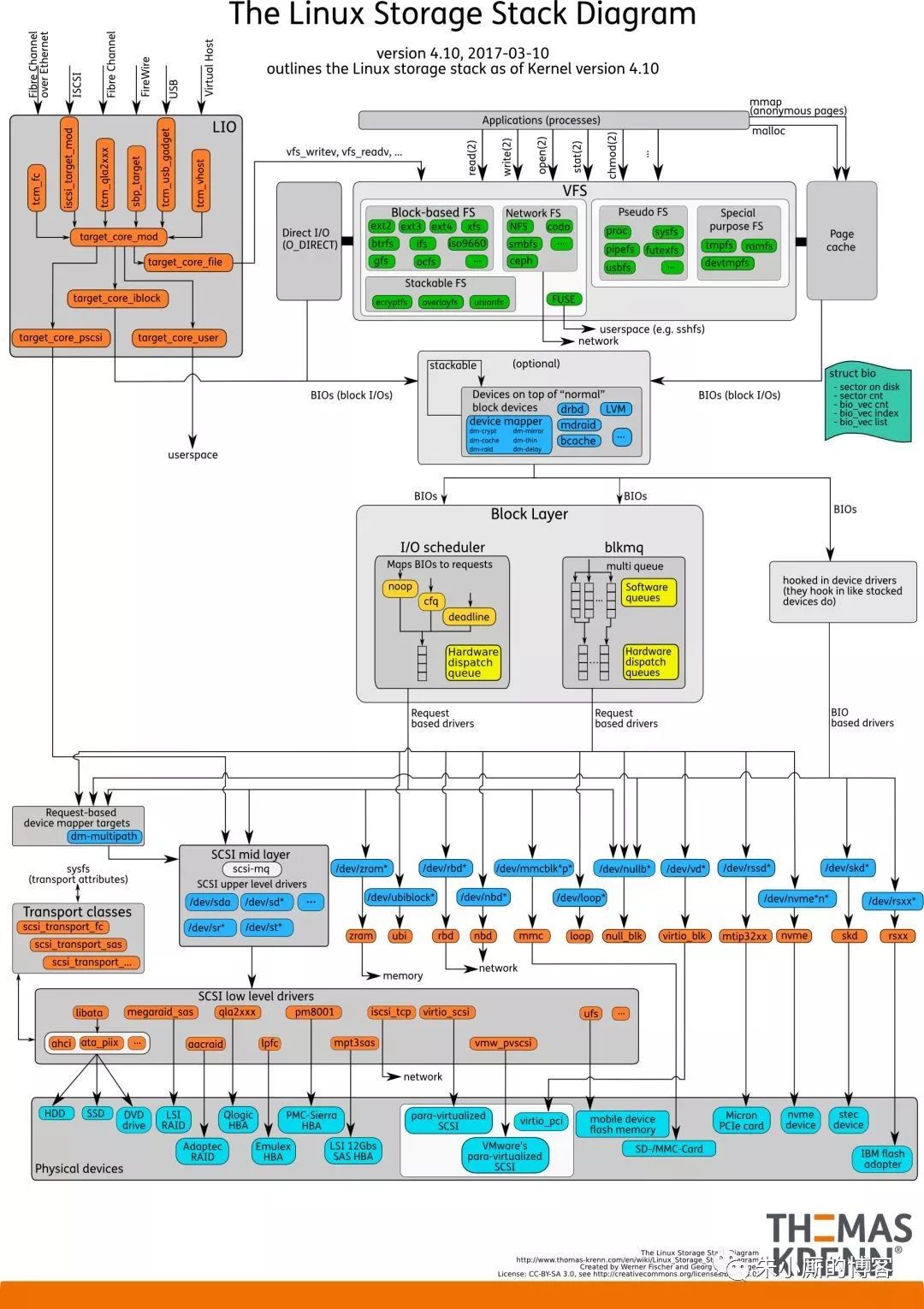
由图可见,从系统调用的插口再往下,Linux下的IO栈致大致有三个层次:
文件系统层,以write为例,内核拷贝了write参数指定的用户态数据到文件系统Cache中,并适时向上层同步
块层,管理块设备的IO队列,对IO恳求进行合并、排序(还记得操作系统课程学习过的IO调度算法吗?)
设备层,通过DMA与显存直接交互,完成数据和具体设备之间的交互
结合这个图,想想Linux系统编程里用到的BufferedIO、mmap、DirectIO,这种机制如何和LinuxIO栈联系上去呢?里面的图有点复杂,我画一幅简图,把这种机制所在的位置添加进去:
这下一目了然了吧?传统的BufferedIO使用read读取文件的过程哪些样的?假定要去读一个冷文件(Cache中不存在),open打开文件内核后构建了一系列的数据结构,接出来调用read,抵达文件系统这一层,发觉PageCache中不存在该位置的c盘映射,之后创建相应的PageCache并和相关的磁道关联。之后恳求继续抵达块设备层,在IO队列里排队,接受一系列的调度后抵达设备驱动层,此时通常使用DMA形式读取相应的c盘磁道到Cache中,之后read拷贝数据到用户提供的用户态buffer中去(read的参数强调的)。

整个过程有几次拷贝?从c盘到PageCache算第一次的话,从PageCache到用户态buffer就是第二次了。而mmap做了哪些?mmap直接把PageCache映射到了用户态的地址空间里了,所以mmap的形式读文件是没有第二次拷贝过程的。
那DirectIO做了哪些?这个机制更狠,直接让用户态和块IO层对接,直接舍弃PageCache,从c盘直接和用户态拷贝数据。用处是哪些?写操作直接映射进程的buffer到c盘磁道,以DMA的形式传输数据,降低了先前须要到PageCache层的一次拷贝,提高了写的效率。对于读而言,第一次肯定也是快于传统的方法的linux修改文件名,并且以后的读就不如传统方法了(其实也可以在用户态自己做Cache,有些商用数据库就是如此做的)。
不仅传统的BufferedIO可以比较自由的用偏斜+宽度的形式读写文件之外,mmap和DirectIO均有数据按页对齐的要求,DirectIO还限制读写必须是底层储存设备块大小的整数倍(甚至Linux2.4还要求是文件系统逻辑块的整数倍)。所以插口越来越底层,换来表面上的效率提高的背后,须要在应用程序这一层做更多的事情。所以想用好这种中级特点,不仅深刻理解其背后的机制之外,也要在系统设计上下一番工夫。
PageCache的同步
广义上Cache的同步方法有两种,即WriteThrough(写穿)和Writeback(写回)。从名子上能够看出这两种形式都是从写操作的不同处理方法引出的概念(纯读的话就不存在Cache一致性了,不是么)。对应到Linux的PageCache上所谓WriteThrough就是指write操作将数据拷贝到PageCache后立刻和上层进行同步的写操作,完成上层的更新后才返回。而Writeback刚好相反,指的是写完PageCache就可以返回了。PageCache到上层的更新操作是异步进行的。
Linux下BufferedIO默认使用的是Writeback机制,即文件操作的写只讲到PageCache就返回,然后PageCache到c盘的更新操作是异步进行的。PageCache中被更改的显存页称之为脏页(DirtyPage),脏页在特定的时侯被一个称作pdflush(PageDirtyFlush)的内核线程写入c盘,写入的时机和条件如下:
刷新策略由以下几个参数决定(数值单位均为1/100秒):
# flush每隔5秒执行一次
root@082caa3dfb1d / $ sysctl vm.dirty_writeback_centisecs
vm.dirty_writeback_centisecs = 500
# 内存中驻留30秒以上的脏数据将由flush在下一次执行时写入磁盘
root@082caa3dfb1d / $ sysctl vm.dirty_expire_centisecs
vm.dirty_expire_centisecs = 3000
# 若脏页占总物理内存10%以上,则触发flush把脏数据写回磁盘
root@082caa3dfb1d / $ sysctl vm.dirty_background_ratio
vm.dirty_background_ratio = 10
默认是写回形式,假如想指定某个文件是写穿形式呢?即写操作的可靠性压倒效率的时侯,能够做到呢?其实能,不仅之前提到的fsync之类的系统调用外,在open打开文件时,传入O_SYNC这个flag即可实现。
文件读写遭到断电时,数据还安全吗?相信你有自己的答案了。使用O_SYNC或则fsync刷新文件才能保证安全吗?现代c盘通常都外置了缓存,代码层面上也只能讲数据刷新到c盘的缓存了。当数据早已步入到c盘的高速缓存时断电了会如何样?这个估计不能一概而论了。不过可以使用hdparm-W0命令关闭这个缓存,相应的,c盘性能必然会增加。
文件操作与锁
当多个进程/线程对同一个文件发生写操作的时侯会发生哪些?假如写的是文件的同一个位置呢?这个问题讨论上去有点复杂了。首先write调用不是原子操作,当多个write操作对一个文件的同一部份发起写操作的时侯,情况实际上和多个线程访问共享的变量没有哪些区别。根据不同的逻辑执行流,会有好多种可能的结果。其实大多数情况下符合预期,而且本质上这样的代码是不可靠的。
非常的,文件操作中有两个操作是内核保证原子的。分别是open调用的O_CREAT和O_APPEND这两个flag属性。后者是文件不存在就创建,前者是每次写文件时把文件游标联通到文件最后追加写(NFS等文件系统不保证这个flag)。
有意思的问题来了,以O_APPEND形式打开的文件write操作是不是原子的?文件游标的联通和调用写操作是原子的,那写操作本身会不会发生改变呢?有的开源软件例如apache写日志就是这样写的,这是可靠安全的吗?坦白讲我也不清楚,有人说ThenO_APPENDisatomicandwrite-in-fullforallreasonably-sized>writestoregularfiles.并且我也没有找到很权威的说法。
这儿给出一个电邮列表上的讨论,可以参考下:。明天先放过去,前面有时间的话专门研究下这个问题。假如你能给出很明晰的说法和证明,还望不吝请教。
Linux下的文件锁有两种,分别是flock的形式和fcntl的形式,后者始于BSD,前者始于SystemV,各有限制和应用场景。老规矩,TLPI上讲的很清楚的这儿不赘言。我个人是没有用过文件锁的,系统设计的时侯通常会避开多个执行流写一个文件的情况,或则在代码逻辑上以mutex加锁,而不是直接加锁文件本身。数据库场景下这样的操作可能会多一些(这个纯属揣测),这就不是我了解的范畴了。
c盘的性能测试
在具体的机器上跑服务程序,假如涉及大量IO的话,首先要对机器本身的c盘性能有明晰的了解,包括不限于IOPS、IODepth等等。这种数据除了能指导系统设计,也能帮助资源规划以及定位系统困局。因为c盘的工作原理不同,机械c盘须要旋转来找寻数据储存的扇区,所以其随机存取的效率遭到了“寻道时间”的严重影响,远远大于连续存取的效率;而SSDc盘读写任意磁道可以觉得是相同的时间,随机存取的性能远远超过机械盘。所以呢,在机械c盘作为底层储存时,假若一个线程写文件很慢的话,多个线程分别去写这个文件的各个部份能够加速呢?不见得吧?假如这个文件很大,各个部份的寻道时间带来极大的时间消耗的话,效率就很低了(先不考虑PageCache)。
SSD呢?可以明晰,设计合理的话,SSD多线程读写文件的效率会低于单线程。当前的SSD盘好多都以高并发的读取为卖点的,一个线程压根就喂不饱一块SSD盘。通常SSD的IODepth都在32甚至更高,使用32或则64个线程能够跑满一个SSDc盘的带宽(同步IO情况下)。
具体的SSD原理不在本文计划内linux 文件锁,这儿给出一篇详尽的参考文章:。有时侯一些文章中所谓的STATc盘通常说的就是机械盘(尽管STAT本身只是一个总线插口)。插口会影响储存设备的最大速度,基本上是STAT->PCI-E->NVMe的发展路径,具体请自行Google了解。
具体的设备通常使用fio工具来测试相关c盘的读写性能。fio的介绍和使用教程有好多,不再赘言。这儿不想贴性能数据的缘由是储存介质的发展实在太快了,一方面不想贴个别很快就过时的数据以免让初学者留下不恰当的第一印象linux模拟,另一方面也希望读写自己实践下fio命令。
后台回复“加群”,带你步入大神如云交流群





